又来一规范--Skills
一个字:牛
Skills 在我看来解决的最大的一个痛点就是 Token爆炸(tools太多),原因如下。
Skills 牛在三层渐进式披露架构
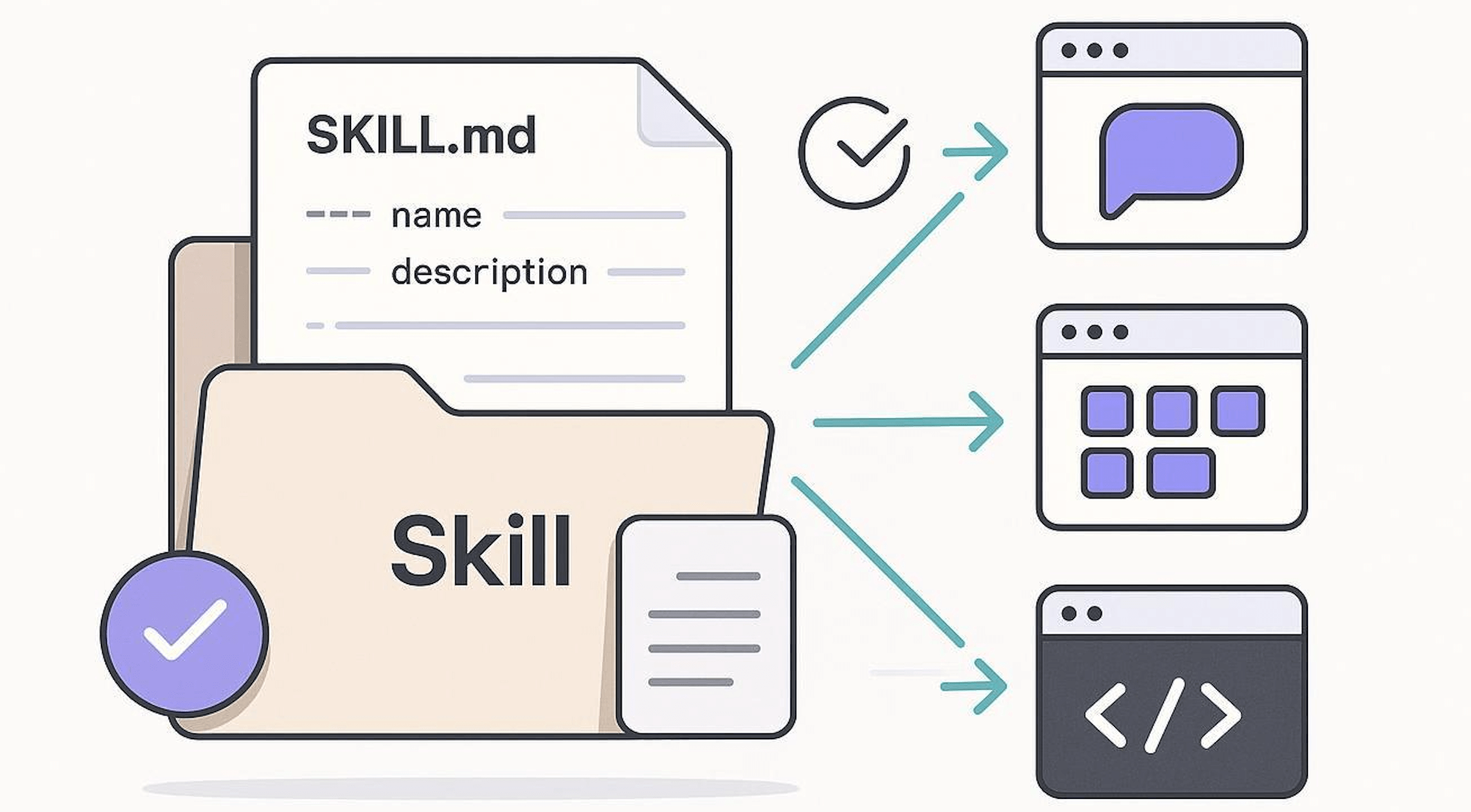
核心就是:一个文件夹 + 一个 SKILL.md 文件。
SKILL.md 文件包含:
元数据(至少要有名称和描述)
告诉 AI 如何完成某一特定任务的指令
一个 Skill 本质上就是一个 Markdown 文件(文件名固定为 SKILL.md)
my-skill/
└── SKILL.md (唯一必需)SKILL.md 基本模板:
---
name: pdf-processing
description: 从 PDF 中提取文本和表格,填写表单,并合并文档
---
# PDF 处理
## 使用场景
当需要对 PDF 文件进行操作时使用,例如:
- 提取 PDF 文本或表格数据
- 填写 PDF 表单
- 合并多个 PDF 文件
## 提取文本
- 使用 `pdfplumber` 提取文本型 PDF 内容
- 扫描版 PDF 需配合 OCR 工具
## 填写表单
- 读取 PDF 表单字段
- 按输入数据填充并生成新文件 最小必填示例:
---
name: skill-name
description: 说明该 Skill 的功能以及适用场景
---含可选字段示例:
---
name: pdf-processing
description: 从 PDF 中提取文本和表格,填写表单,并合并文档
license: Apache-2.0
metadata:
author: example-org
version: "1.0"
---如果你需要一些参考资料,参考实例,执行脚本,可以使用更复制 Skill 的目录结构:
my-skill/
├── SKILL.md # 必需:指令 + 元数据
├── scripts/ # 可选:可执行代码
├── references/ # 可选:文档资料
└── assets/ # 可选:模板、资源
总结
之前说MCP包Tools,现在Skills包一切啊。为个性化agent打开了想象空间。
Skills 可以组合一切,定义执行流程。
Skills 用渐进式加载来高效管理上下文:
发现:启动时,AI 只加载每个技能的名称和描述,只保留最基本的识别信息。
激活:当任务匹配某个技能的描述时,AI 才把完整的 SKILL.md 指令读入上下文。
执行:AI 按照指令执行,按需加载参考文件或运行代码。
这种设计让 AI 保持快速,同时能按需获取更多信息。
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 故宫而过
阅读建议





评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果