6 Core Orchestration Patterns
LLM架构的6种核心编排模式分析
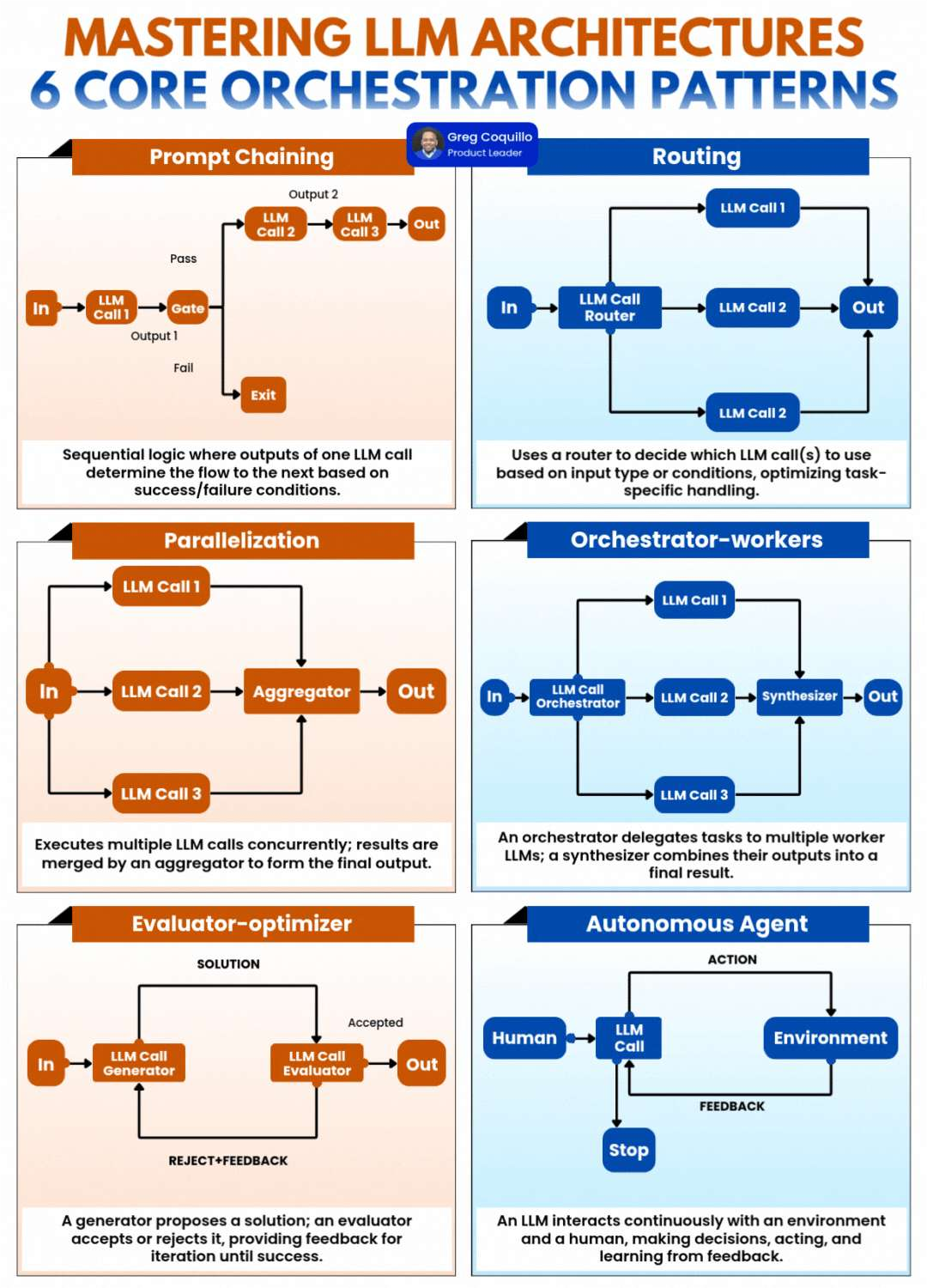
这幅图展示了由产品经理Greg Cuilioli提出的「LLM架构的6种核心编排模式」(6 Core Orchestration Patterns),这些模式用于优化大语言模型在复杂任务中的应用。
一、模式分类
根据模式的核心功能和应用场景,可以将这6种模式分为两大类:
1. 流程控制类(橙色系)
Prompt Chaining(提示链)
Parallelization(并行化)
Evaluator-optimizer(评估器-优化器)
2. 资源分配与自主决策类(蓝色系)
Routing(路由)
Orchestrator-workers(编排器-工作者)
Autonomous Agent(自主代理)
二、详细解读与案例分析
1. 流程控制类模式
1.1 Prompt Chaining(提示链)
核心原理:采用顺序逻辑,一个LLM调用的输出决定下一个调用的流程,基于成功/失败条件进行分支处理。
应用场景:需要多步骤推理的复杂任务,如问题拆解、多轮对话、代码生成等。
案例:复杂问题求解
# 使用LangChain实现提示链示例
from langchain import LLMChain, PromptTemplate
from langchain.llms import OpenAI
# 第一步:问题拆解
step1_prompt = PromptTemplate(
input_variables=["question"],
template="将问题拆分为更小的子问题:{question}"
)
step1_chain = LLMChain(llm=OpenAI(), prompt=step1_prompt)
# 第二步:逐一解决子问题
step2_prompt = PromptTemplate(
input_variables=["sub_questions"],
template="逐一解决以下子问题:{sub_questions}"
)
step2_chain = LLMChain(llm=OpenAI(), prompt=step2_prompt)
# 第三步:综合答案
step3_prompt = PromptTemplate(
input_variables=["sub_answers"],
template="综合以下子问题答案,形成最终回答:{sub_answers}"
)
step3_chain = LLMChain(llm=OpenAI(), prompt=step3_prompt)
# 执行链
question = "如何使用Python实现快速排序算法?"
sub_questions = step1_chain.run(question)
sub_answers = step2_chain.run(sub_questions)
final_answer = step3_chain.run(sub_answers)
1.2 Parallelization(并行化)
核心原理:同时执行多个LLM调用,结果由聚合器合并形成最终输出。
应用场景:需要从不同角度分析问题、批量处理任务、提高处理速度等。
案例:多维度文本分析
# 使用LangChain实现并行处理
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableParallel
# 定义多个分析维度
analysis_tasks = RunnableParallel(
sentiment=ChatPromptTemplate.from_template("分析以下文本的情感:{text}") | ChatOpenAI() | StrOutputParser(),
keywords=ChatPromptTemplate.from_template("提取以下文本的关键词:{text}") | ChatOpenAI() | StrOutputParser(),
summary=ChatPromptTemplate.from_template("总结以下文本的主要内容:{text}") | ChatOpenAI() | StrOutputParser()
)
# 执行并行分析
text = "今天天气很好,我和朋友一起去公园散步,欣赏了美丽的花朵,心情非常愉快。"
results = analysis_tasks.invoke({"text": text})
# 输出结果
print(f"情感分析:{results['sentiment']}")
print(f"关键词:{results['keywords']}")
print(f"摘要:{results['summary']}")
1.3 Evaluator-optimizer(评估器-优化器)
核心原理:生成器提出解决方案,评估器接受或拒绝,提供反馈进行迭代直到成功。
应用场景:需要高质量输出的任务,如论文写作、代码优化、方案设计等。
案例:代码优化
# 简单的评估器-优化器实现
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
# 初始化模型
llm = ChatOpenAI()
output_parser = StrOutputParser()
# 定义生成器提示
generator_prompt = ChatPromptTemplate.from_template(
"优化以下Python代码,使其更高效:{code}"
)
# 定义评估器提示
evaluator_prompt = ChatPromptTemplate.from_template(
"评估以下优化后的代码是否满足要求:
原代码:{original_code}
优化代码:{optimized_code}
评估标准:
1. 功能是否保持一致
2. 性能是否有所提升
3. 代码可读性是否良好
如果满足所有标准,输出'ACCEPTED';否则输出具体的改进建议。"
)
# 原代码
original_code = """
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
"""
# 执行迭代优化
max_iterations = 3
success = False
for i in range(max_iterations):
# 生成优化代码
generator_chain = generator_prompt | llm | output_parser
optimized_code = generator_chain.invoke({"code": original_code})
# 评估优化结果
evaluator_chain = evaluator_prompt | llm | output_parser
evaluation = evaluator_chain.invoke({
"original_code": original_code,
"optimized_code": optimized_code
})
if "ACCEPTED" in evaluation:
success = True
print(f"优化成功!")
print(f"优化后的代码:\n{optimized_code}")
break
else:
print(f"第{i+1}次优化未通过评估:{evaluation}")
# 使用评估结果作为反馈继续优化
original_code = optimized_code
if not success:
print("在最大迭代次数内未获得满意的优化结果")
2. 资源分配与自主决策类模式
2.1 Routing(路由)
核心原理:使用路由器根据输入类型或条件决定使用哪个LLM调用,优化特定任务的处理。
应用场景:处理多种类型请求的系统,如多模态处理、不同领域问题等。
案例:多类型请求处理系统
# 简单的路由实现
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI, ChatAnthropic
from langchain.schema.output_parser import StrOutputParser
# 初始化不同模型
openai_llm = ChatOpenAI()
anthropic_llm = ChatAnthropic()
# 定义路由函数
def route_request(input_text):
# 使用简单的规则进行路由
if "代码" in input_text or "编程" in input_text:
return "code"
elif "创意" in input_text or "写作" in input_text:
return "creative"
else:
return "general"
# 定义不同任务的处理链
code_prompt = ChatPromptTemplate.from_template("编写{language}代码实现{功能}")
code_chain = code_prompt | openai_llm | StrOutputParser()
creative_prompt = ChatPromptTemplate.from_template("生成关于{topic}的创意内容")
creative_chain = creative_prompt | anthropic_llm | StrOutputParser()
general_prompt = ChatPromptTemplate.from_template("回答问题:{question}")
general_chain = general_prompt | openai_llm | StrOutputParser()
# 处理请求的主函数
def handle_request(request):
route = route_request(request)
if route == "code":
return code_chain.invoke({"language": "Python", "功能": request})
elif route == "creative":
return creative_chain.invoke({"topic": request})
else:
return general_chain.invoke({"question": request})
# 测试
requests = [
"编写Python代码实现快速排序",
"生成关于人工智能未来的创意故事",
"解释量子计算的基本原理"
]
for req in requests:
print(f"请求:{req}")
print(f"路由:{route_request(req)}")
print(f"响应:{handle_request(req)}")
print("---")
2.2 Orchestrator-workers(编排器-工作者)
核心原理:一个编排器将任务委托给多个工作者LLM,一个合成器将它们的输出合并为最终结果。
应用场景:需要多人协作或多专业知识的复杂任务,如市场研究、产品设计、多语言翻译等。
案例:多语言翻译与校对
# 简单的编排器-工作者实现
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableParallel
# 初始化模型
llm = ChatOpenAI()
output_parser = StrOutputParser()
# 定义工作者任务
workers = RunnableParallel(
english=ChatPromptTemplate.from_template("将文本翻译成英语:{text}") | llm | output_parser,
french=ChatPromptTemplate.from_template("将文本翻译成法语:{text}") | llm | output_parser,
spanish=ChatPromptTemplate.from_template("将文本翻译成西班牙语:{text}") | llm | output_parser
)
# 定义合成器
synthesizer_prompt = ChatPromptTemplate.from_template(
"整理以下多语言翻译结果,格式化为清晰的表格:
英语翻译:{english}
法语翻译:{french}
西班牙语翻译:{spanish}"
)
# 完整流程
def orchestrate_translation(text):
# 工作者执行翻译
translations = workers.invoke({"text": text})
# 合成器整理结果
synthesizer = synthesizer_prompt | llm | output_parser
result = synthesizer.invoke(translations)
return result
# 测试
text = "人工智能正在改变我们的生活方式,从工作到娱乐,从医疗到教育。"
result = orchestrate_translation(text)
print(result)
2.3 Autonomous Agent(自主代理)
核心原理:LLM与环境和人类持续交互,做出决策、采取行动并从反馈中学习。
应用场景:需要自主决策和行动的复杂任务,如个人助理、客户服务、研究助手等。
案例:简单的自主研究助手
# 简化的自主代理实现
import requests
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
# 初始化模型
llm = ChatOpenAI()
output_parser = StrOutputParser()
# 定义代理的核心功能
class ResearchAgent:
def __init__(self):
self.history = []
def plan_research(self, topic):
prompt = ChatPromptTemplate.from_template(
"制定关于{topic}的研究计划,包括需要查找的关键点和信息来源。"
)
chain = prompt | llm | output_parser
return chain.invoke({"topic": topic})
def search_information(self, query):
# 简化的搜索功能(实际应用中可使用SerpAPI等)
print(f"搜索:{query}")
# 模拟搜索结果
return f"关于{query}的搜索结果摘要..."
def analyze_information(self, search_results):
prompt = ChatPromptTemplate.from_template(
"分析以下搜索结果,提取关键信息:{results}"
)
chain = prompt | llm | output_parser
return chain.invoke({"results": search_results})
def generate_report(self, analysis):
prompt = ChatPromptTemplate.from_template(
"根据以下分析结果生成一份结构化的研究报告:{analysis}"
)
chain = prompt | llm | output_parser
return chain.invoke({"analysis": analysis})
def run(self, topic, max_iterations=3):
print(f"开始研究:{topic}")
# 1. 制定研究计划
plan = self.plan_research(topic)
self.history.append(f"计划:{plan}")
print("\n研究计划:")
print(plan)
# 2. 执行研究(简化版,实际可根据计划进行多轮搜索)
search_results = self.search_information(topic)
self.history.append(f"搜索结果:{search_results}")
print("\n搜索结果:")
print(search_results)
# 3. 分析信息
analysis = self.analyze_information(search_results)
self.history.append(f"分析:{analysis}")
print("\n信息分析:")
print(analysis)
# 4. 生成报告
report = self.generate_report(analysis)
self.history.append(f"报告:{report}")
print("\n研究报告:")
print(report)
return report
# 测试代理
agent = ResearchAgent()
agent.run("人工智能在医疗领域的应用现状与未来趋势")
三、总结
这6种核心编排模式为LLM的工程化应用提供了强大的框架:
流程控制类模式通过合理安排LLM调用的顺序、并行性和迭代过程,提高了复杂任务的处理能力和输出质量。
资源分配与自主决策类模式通过智能选择模型、分配任务和自主决策,优化了资源利用,实现了更灵活、更强大的LLM应用。
在实际工程化应用中,这些模式可以根据需求组合使用,构建出更复杂、更高效的LLM系统。例如,一个智能客服系统可能同时使用Routing(根据用户请求类型选择不同模型)、Prompt Chaining(处理多轮对话)和Autonomous Agent(自主决策如何响应用户)等多种模式。