LoRa--llama2-7b fine-tuning实践总结
训练平台
Nvida 4090 24G
为什么选择llama2-7b
主要是因为显存大小限制,llama2-7b半精度,推理13G,实际使用会增加到17G,量化后会压缩。微调Lora时根据参数调节有时候会超过24G用到共享内存。
用什么平台训练
05 ‐ Training Tab · oobabooga/text-generation-webui Wiki · GitHub
LoRA Training | oobabooga/text-generation-webui | DeepWiki
训练过程
数据集准备,特定格式
{
"instruction,output": "User: %instruction%\nAssistant: %output%",
"instruction,input,output": "User: %instruction%: %input%\nAssistant: %output%"
}训练参数
dataset:用于训练的数据集名称。
format:数据的格式,为"alpaca-chatbot-format"。
cutoff_len:截断长度,为512。影响显存
overlap_len:重叠长度,为128。
hard_cut_string:硬截断字符串,为"\n\n\n"。
lora_name:表示LoRA的名称。
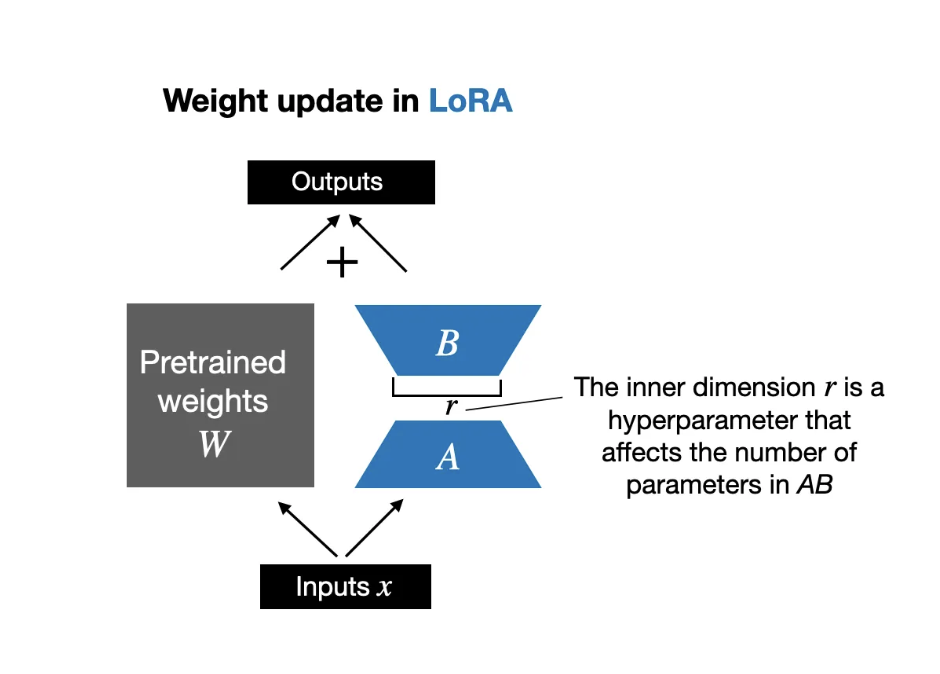
lora_rank:LoRA的rank值,为16。尽量2的指数。秩的大小决定了模型的大小
lora_alpha:LoRA的alpha值,为32。权重缩放参数,lora_alpha/lora_rank得到一个系数,通常秩的两倍,模型收敛慢就适当加大,如果过拟合就适当减小。
batch_size:每个批次的样本数,为128。决定梯度稳定性,越大收敛越稳定,但需更多显存或梯度累积
micro_batch_size:每个微批次的大小,为4。用时间换显存。梯度累计步数=batch_size/micro_batch_size
always_override:如果为true,则始终覆盖现有的保存点或模型。
save_steps:每隔多少步保存一次模型。值为0.0表示不保存。
epochs:总共要训练的轮数(epoch),为3.0。整个训练数据集被完整遍历的次数。总步数=epochs*数据集样本数量/micro_batch_size
learning_rate:学习率,为3e-4。每次训练权重变化的幅度
lr_scheduler_type:学习率调度器的类型,这里使用的是线性学习率调度器。
warmup_steps:预热步数,为100.0。
stop_at_loss:当损失达到特定值时停止训练。
lora_dropout:LoRA的dropout率,为0.05。
eval_dataset:用于评估的数据集名称,为"school_math_val"。
eval_steps:每隔多少步进行一次评估,为100.0。
raw_text_file:原始文本文件的路径,这里为"None"。
newline_favor_len:新行优先长度,为128。
higher_rank_limit:是否有更高的rank限制,这里为false。
optimizer:使用的优化器,为"adamw_torch"。
train_only_after:仅在特定条件后开始训练,这里为空字符串。
add_eos_token:是否在每个序列的末尾添加EOS(End of Sequence)标记,这里为false。
min_chars:最小字符数,为0.0。
report_to:报告的目的地,这里为"None"。
用到了哪些技术框架?
transformers、torch、PEFT(Parameter-Efficient Fine-Tuning)
transformers初始化模型
peft注入Lora参数
torch开始训练
lr_scheduler_type 学习率调度器
恒定、线性衰减、余弦衰减
再结合warmup,达到稳定训练
warmup_steps 预热步数
缓解训练初期的不稳定性,学习率逐步加载到设置的值
总步数的1%慢慢加,直到一个合适的参数
怎么判断拟合程度?
training loss 稳步下降后趋于稳定,如果一直卡在高位比如说2就欠拟合,如果损失值骤降活很低0.1结合生成效果差过拟合
validation loss 停止下降开始上升表示过拟合
数据集怎么处理?
人工标注,处理成固定格式
文本截断加上重叠文本会影响样本数量,在资源充足的情况下,尽量不要截断,保留完整的上下文
训练一次时间是多久?
控制总步数,预热步数,秩的大小,梯度累积,整体在4小时左右,保证半个工作日能出结果。
LoRA作用域是在哪?
LoRA(Low-Rank Adaptation)主要作用于Transformer层 (Layer 0 - N),融合到权重矩阵,特别是对 注意力机制(Attention) 和 前馈网络(FFN) 起作用。 维度d*d变成 d*r r*d
还有什么推理框架?
llamafactory 专门训练模型的,提供了跟多的fine-tuning方式
有哪些微调方法?
Lora以及其变种作用于权重比较通用(文字,图片),平衡效率和性能
P-tuning v2,有时候prompt的构造效果也会影响下游的效果,将prompt进行微调,而且对每一层都添加入,适合文本生成
总结
深刻理解了什么叫 调参(算法)工程师
不断训练、验证和试错,犹如炼丹,获取金丹是个概率性事件,而且还是不能复现的
所以训练框架的训练和验证速度才是王道